


Is postgresql can do average for rolling data? I have this case where I need to average the values for 5 days and get all the days filled up while waiting for the actual values so basically if I’m in day 6 today, my formula would be day 1-5 then day 7 would be 2-6 but day 6 values comes from the average today and so on. You can see the values below. I have been searching if sql can do this but can’t find any function. I only found recursive but not available in postgres.
SAMPLE TABLE
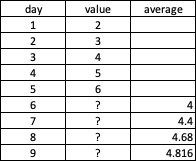
2
Answers
The key to calculating rolling means with missing value substitution is to maintain a buffer holding the values contributing to the mean. The following query demonstrates calculating a rolling mean using a recursive CTE with an array holding the contributing values:
I don’t have access to a postgreSQL 9.1 database, so I have only run this with PostgreSQL 15.3. There might be some changes needed for the older version; however, the general concepts still apply.
You can get what the 5-day running average you asked for with the window version of the avg() function, see here and here with demo here.
Well at least you get what you asked for, 5 day prior average. You cannot however get what you have in your
sample tableas days 6 thru 10 do not have a valid value and I am not going to what values you lead to your posed results.NOTE: Demo actually run with v15. As v9.1 is no longer carried by db<>fiddle, but documentation references are v9.1.