


Please help with self join inside one table by different fields. given table "Items":
Used PostgreSQL.
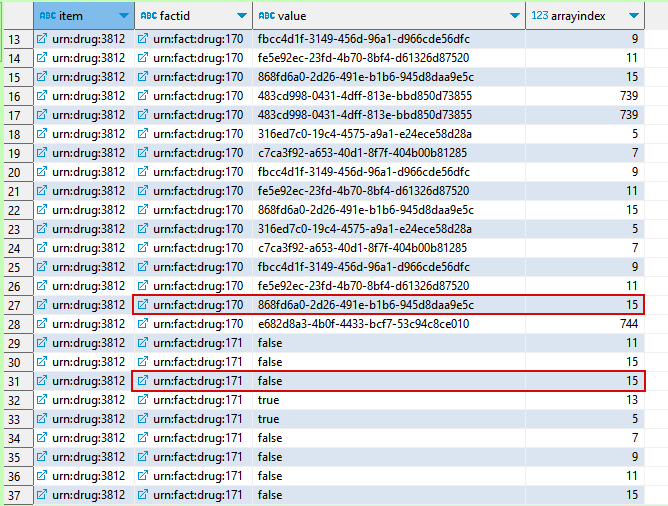
I need to get all the values from such table, for which factId = 'urn:fact:drug:170' and factId1 ='urn:fact:drug:171' and factId1.value ='false' and arrayIndexes are the same.
It means factId 170 & 171 have relation one-to one using the same arrayIndex.
So all the values of factId 'urn:fact:drug:170' are needed, for which there is related by same arrayIndex factId 'urn:fact:drug:171' which have value 'false'.
Here is column Item in the table, it means for each Item we have own set of values 170 and 171.
Thank you.
I tryed this but I am not sure this works fine and fast:
SELECT l.value
FROM Items l
INNER JOIN Items p on p.item = l.item
INNER JOIN Items c on c.item = l.item
WHERE l.factid = 'urn:fact:drug:170' AND c.factid = 'urn:fact:drug:170'
AND p.factid = 'urn:fact:drug:171' AND p.value='false'
AND p.arrayindex = l.arrayindex
there are a lot of duplicates after work.
Please check my query.
2
Answers
Your query can be:
DB fiddle
Details:
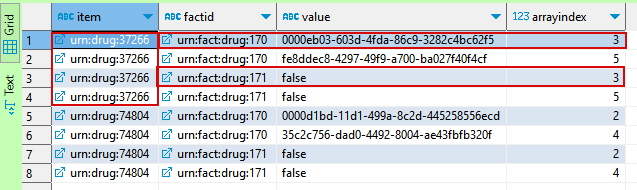
tCTE query finds uniquearrayindexvalues for all rows which fulfill the conditionwhere factid = 'urn:drug:171' and value = 'false';factid = 'urn:drug:170'. Result rows are filtered by thearrayindexvalues which we received from the previous step.Your apparent problem are the duplicates in the source table.
The
170row appears 3 times in your date, the171row two times.To get a one-to one relation you must must somehow introduce a unique identification – I use the
row_number.Than it is a plain join with additional predicate on the row number
Query (with sample data as CTE)
Result
So you can join two rows, the third is skipped as there is no match on both sides