


{kind=link}
Hello!!
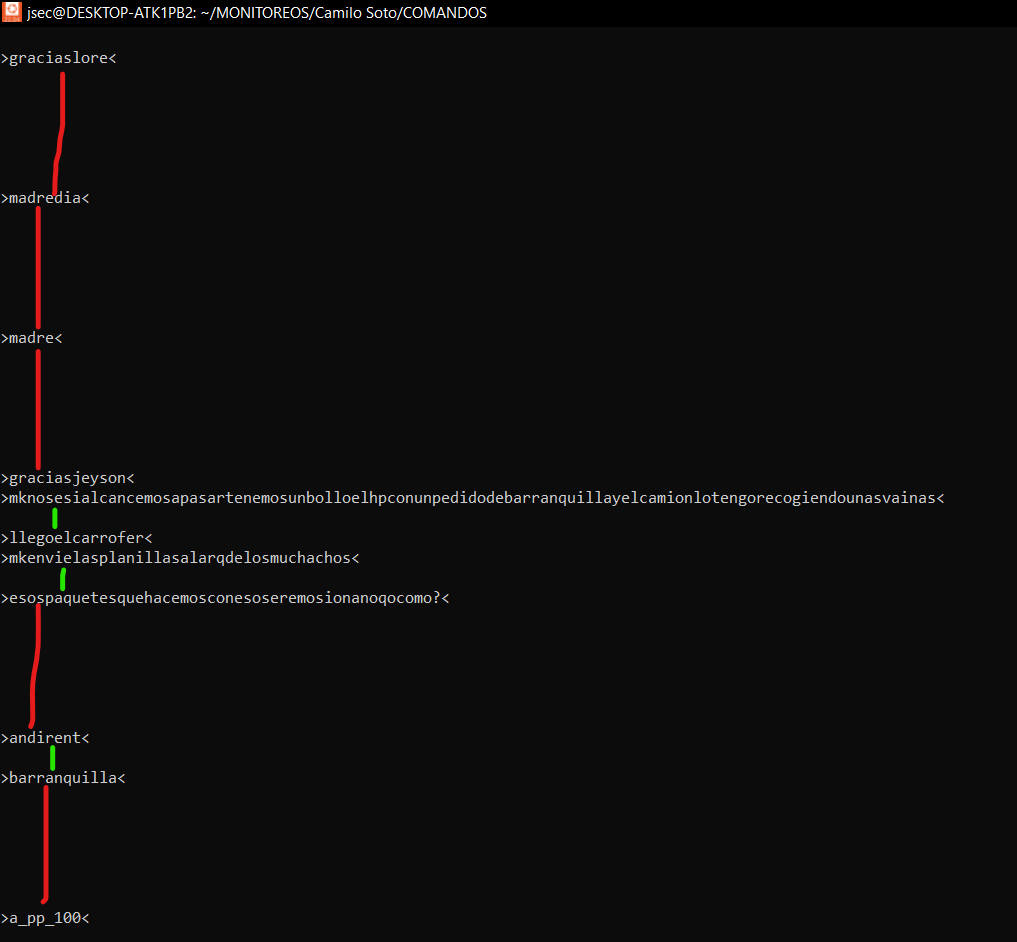
As it says in the title, I need to remove the white spacing that separate only by a white spacing to two lines, as you see in the image, the white spacing that have a green line, are the ones I need to remove, but the multiple white spacing that are with a red line, I do not want to remove them, the ones with the green line, are separated by only a white spacing, I do not know if with AWK or SED or CUT will work, the problem is that I do not know how to do it, thank you for your help.
I tried to do it with SED and with AWK as follows, but it did not produce any effect
awk -F, '{gsub("n","",$1); print}' archivo.txt
sed 's/ //g' input.txt > no-spaces.txt
3
Answers
Assumptions:
of the file.
If
GNU sedwhich supports-z(slurp) option andnnotation isavailable. would you please try:
Example of
input.txt:Output:
Sednormally processes the input line by line. That is why we cannot processthe input across multiple lines. The
-zoption changes the behavior bysetting the input line separator to the NUL character.
([^n]n)matches the last character of non-blank line.1is set as a backreference.
nis the blank line in between (to be removed).([^n])matches the first character of the following non-blank line.2isset as a backreference.
Btw following will work with any POSIX-compliant sed with a help of
bash:With any
awk:If the current line contains only spaces (
/^[[:space:]]*$/) increment variablen, store current line in variablep, and move to next line (next). Else (the current line contains non-space characters), ifn==1print the previous empty line stored in variablep, then print the current line and resetn.Note: if the last line contains only spaces and is preceded by a line containing non-space characters, it is not printed. If it must be printed try:
Note: if you want to remove only empty lines, replace
^[[:space:]]*$/with/^$/.This might work for you (GNU sed):
Open a 3 line window.
If a two non-empty lines sandwich an empty line, remove the empty line and maintain the 3 line window.
Otherwise, print/delete the first line and repeat.
N.B.
1Nensures the 3 line window is created, theNfollowing the substitution ensures this likewise.