


I am on intel dev cloud and using Intel OneAPI. This is my code till now:
# first block of jupyter notebook
import modin.pandas as pd
# second block of jupyter notebook
df = pd.read_csv('dataset/dataset.csv')
df.head()
# output of second block
UserWarning: Ray execution environment not yet initialized. Initializing...
To remove this warning, run the following python code before doing dataframe operations:
import ray
ray.init()
2023-09-01 12:00:16,471 INFO worker.py:1636 -- Started a local Ray instance.
The first block is running properly but, when I am reading my dataset, it is giving me this warning and server unavailable error.
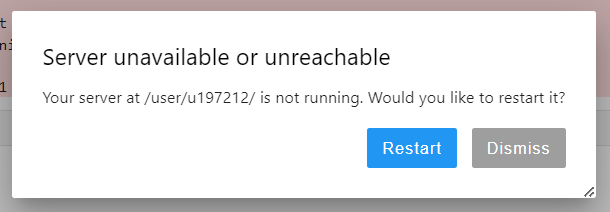
If I use import pandas as pd, the code is running fine, but modin.pandas is not working. My dataset is ~ 1 GB csv file. Why is this happening???
How to Reproduce this?
- Step 1 – https://devcloud.intel.com/oneapi/
- Step 2 – click on Getting
Started tab. - Step 3 – Go down and Click on launch JupyterLab. (It is
like Google Colab or Kaggle Notebooks) - Step 4 – Create ipynb and use
wget to download this data. - Data – !wget
https://s3-ap-southeast-1.amazonaws.com/he-public-data/datasetab75fb3.zip
System Information
- OS – Linux 90-Ubuntu 5.4.0-80-generic
- CPU – Intel(R) Xeon(R) Gold 6128 CPU @ 3.40GHz
- RAM – 188 GB
2
Answers
Step 1: Check if you have installed modin properly. If you are unsure, try to reinstall the relevant modin dependencies etc.
Step 2: import modin.pandas as pd
Let’s see what will happen.
Reference:
The pandas library offers user-friendly data structures, including DataFrames, for data analysis. However, it may perform slowly with extensive datasets (e.g., 100 GB or 1 TB) since it wasn’t optimized for such large volumes. Fortunately, the Modin library addresses this by allowing you to scale pandas workflows with just one code change.
Answered in Intel DevCloud support, please take a look