 Question posted in
Question posted in 

Problem: Following a quicksart guide in official docs (https://mlflow.org/docs/latest/tracking/autolog.html), every time I try running mlflow ui --port 8080 inside parent directory with particular conda env activated same error keeps popping up:
C:Usersuserminiconda3envsregularLibsite-packagespydantic_internal_config.py:322: UserWarning: Valid config keys have changed in V2:
* 'schema_extra' has been renamed to 'json_schema_extra'
warnings.warn(message, UserWarning)
Traceback (most recent call last):
File "<frozen runpy>", line 198, in _run_module_as_main
File "<frozen runpy>", line 88, in _run_code
File "C:Usersuserminiconda3envsregularScriptsmlflow.exe__main__.py", line 4, in <module>
File "C:Usersuserminiconda3envsregularLibsite-packagesmlflowcli.py", line 356, in <module>
type=click.Choice([e.name for e in importlib.metadata.entry_points().get("mlflow.app", [])]),
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AttributeError: 'EntryPoints' object has no attribute 'get'
I have tried multiple versions, reinstalling importlib-metadata (following same issue 'EntryPoints' object has no attribute 'get' – Digital ocean), installing older versions prior to mlflow=2.10.0 as well as older versions of pydantic prior to pydantic==2.6.1 (following the advice of @BenWilson2 from DataBricks on MLflow GH issues). Would really appreciate if anyone could help me wrap my head around the issue. Thanks in advance.
Project structure:

regModel.py:
import warnings
import argparse
import logging
import pandas as pd
import numpy as np
import mlflow
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
from sklearn.model_selection import train_test_split
from sklearn.linear_model import ElasticNet
logging.basicConfig(level=logging.WARN)
logger = logging.getLogger(__name__)
#evaluation function
def eval_metrics(actual, pred):
rmse = np.sqrt(mean_squared_error(actual, pred))
mae = mean_absolute_error(actual, pred)
r2 = r2_score(actual, pred)
return rmse, mae, r2
def run_experiment(alpha, l1_ratio):
warnings.filterwarnings("ignore")
# Read the wine-quality csv file from local
data = pd.read_csv("data/red-wine-quality.csv")
data.to_csv("data/red-wine-quality.csv", index=False)
# Split the data into training and test sets. (0.75, 0.25) split.
train, test = train_test_split(data)
# The predicted column is "quality" which is a scalar from [3, 9]
train_x = train.drop(["quality"], axis=1)
test_x = test.drop(["quality"], axis=1)
train_y = train[["quality"]]
test_y = test[["quality"]]
lr = ElasticNet(alpha=alpha, l1_ratio=l1_ratio, random_state=42)
lr.fit(train_x, train_y)
predicted_qualities = lr.predict(test_x)
(rmse, mae, r2) = eval_metrics(test_y, predicted_qualities)
print("Elasticnet model (alpha={:f}, l1_ratio={:f}):".format(alpha, l1_ratio))
print(" RMSE: %s" % rmse)
print(" MAE: %s" % mae)
print(" R2: %s" % r2)
mlflow.log_param("alpha", alpha)
mlflow.log_param("l1", l1_ratio)
mlflow.log_metric("rmse", rmse)
mlflow.log_metric("r2", r2)
mlflow.log_metric("mae", mae)
mlflow.sklearn.log_model(lr, "models")
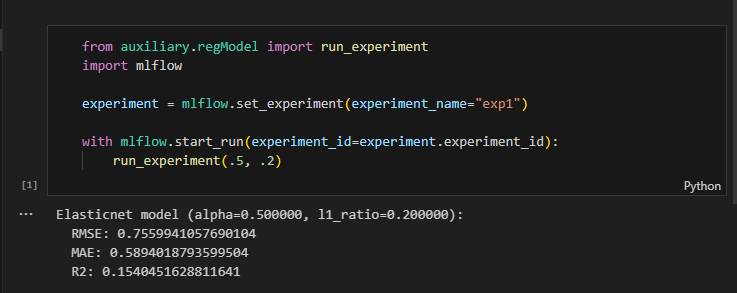
inroduction.ipynb:
2
Answers
Obviously the error was in
cli.py. However the appropriate fix was needed, which, thanks to Gabomfim, has been discovered:Check if the issue is related to
importlib-metadata, as in this article from Borislav Hadzhiev.Or you would need to upgrade other dependencies, as
golosegor/pyspark-nested-fields-functionshad to do to avoid the same error.(From PR #1, referencing
importlib_metadataissue 406)mlflow/mlflowissue 10804 suggests: