


I have created a table using the flask db migrate method.
Below is how my model is
class MutualFundsDataTest(db.Model):
id = db.Column(db.Integer, primary_key=True, autoincrement=True)
Name = db.Column(db.Text, nullable=False)
MF_Code = db.Column(db.Text, nullable=False)
Scheme_Code_Direct = db.Column(db.Text, nullable=True)
Scheme_Code_Regular = db.Column(db.Text, nullable=True)
Sub_Category = db.Column(db.Text, nullable=True)
Plan = db.Column(db.Text, nullable=True)
AUM = db.Column(db.NUMERIC, nullable=True)
Expense_Ratio = db.Column(db.NUMERIC, nullable=True)
Time_Since_Inception = db.Column(db.NUMERIC, nullable=True)
Exit_Load = db.Column(db.NUMERIC, nullable=True)
and I have another script that is responsible for inserting data into the database from an xlsx file. I have specified the datatype for each column which is consistent with the datatype from the above posted model.py file. All my columns should be either TEXT or NUMERIC type.
import pandas as pd
from sqlalchemy import create_engine
from sqlalchemy import types
sql_types = {"Name": types.TEXT(), "MF_Code" : types.TEXT(),"Scheme_Code_Direct" : types.TEXT(),"Scheme_Code_Regular" : types.TEXT(), "Sub_Category" : types.TEXT(), "Plan": types.TEXT(), "AUM" : types.NUMERIC(), "Expense_Ratio" : types.NUMERIC(), "Time_Since_Inception" : types.NUMERIC(), "Exit_Load" : types.NUMERIC()}
df = pd.read_excel('./path_to_xlxs', "sheet_name")
engine= create_engine('postgresql://username:password@localhost:port/database')
df.to_sql('mutual_funds_data_test', con=engine, if_exists='replace', index=False, dtype=sql_types)
But for some reason, pandas is changing the datatypes of the column in the Postgresql database Below is the screenshot of the column from the Postgresql after pandas has changed the column datatype.
Is there any way to force pandas not to change datatype? I am not sure why it is changing it as there is no error. I am following this Documentation1, Documentation2
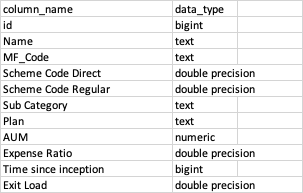
2
Answers
Python pandas: how to specify data types when reading an Excel file? suggests using the
dtypeargument when operatingread_excel.pandas.read_excel says about the dtype argument:
dtypeType name or dict of column -> type, default None
Data type for data or columns. E.g. {‘a’: np.float64, ‘b’: np.int32} Use object to preserve data as stored in Excel and not interpret dtype.
So, something like
dtype = 'object'may be what you seek.Or is it the subsequent export that changes dtypes? Please share df.dtypes after operating
read_excelto remove ambiguity.Your column names in
sql_typeshave underscores, which are not there in the screenshot. You need to rename your columns first to match the dictionary keys.If you define the schema elsewhere, consider not using
if_exists="replace". This would have shown you the schema mismatch immediately.